Big data of the late Middle Ages
The cross-faculty MEPHisto research group investigates and develops digital techniques and tools to support historical research.

By Ute Schönfelder
MEPHisto (»Models, Explanations and Processes in the Historical Sciences«) is an interdisciplinary research group consisting of researchers from the Professorship of Practical Computer Science II (Artificial Intelligence) and the Professorship of Medieval History. Its mission is to investigate and develop digital techniques and tools to support historical research. In a current project, the team led by Prof. Dr Clemens Beckstein and Prof. Dr Robert Gramsch-Stehfest focuses on the digital indexing of what are known as »regesta«. These short, semi-structured texts summarize the content of historical sources in condensed form.
Specifically, this involves sources from the Vatican Archive. »The Roman Curia began to comprehensively document and archive its administrative records in the High Middle Ages. The result is a vast amount of written tradition unlike anything else for the Middle Ages,« says Robert Gramsch-Stehfest. However, the thousands of handwritten tomes in the Vatican are almost entirely inaccessible for a systematic investigation.
Researchers identified this issue over 130 years ago and began to transfer the extensive documentation into semi-structured form. Initiated in 1892, the »Repertorium Germanicum« (RG) project summarizes documents from the Vatican Archives which relate to Germany in a shorthand system. It is »a sort of Latin stenography,« as Clemens Beckstein describes it. To date, the ten volumes of the RG list tens of thousands of clergy members and scholars from 1378 to 1484 and report on the events involving them. However, these summaries are still unsuitable for a comprehensive, computer-aided evaluation.
In order to make them easily usable for a wide range of scientific questions, the MEPHisto team uses AI-based methods to automatically filter out the factual information contained in the RG's regesta and translate it into structured data that can be stored in a conventional database. For this process, the team members rely on ANTLR (ANother Tool for Language Recognition), a parser generator that supports the automatic generation of text analysis tools.

An image of a fictitious syntax tree created with the AI programme Midjourney. The textto- image tool was instructed (prompted) to create a »parse tree in the style of Fra Angelico«. It solved the task by drawing on a form of tree visualization that was very popular in the late Middle Ages and early modern period, the genealogical family tree. Apparently, the AI was trained with corresponding image material. Fra Angelico, a Tuscan artist of the early 15th century, worked in Rome himself. His works—predominantly altarpieces—are characterized by a austere, simple visual language, which Midjourney captures well.
Illustration: MidjourneyBefore they can use algorithms to examine the regesta in relation to a specific research question, the team must first develop a formal grammar that appropriately describes the syntactical structure of the regesta according to the terminology used in these documents (i.e. the canonical terminology of the High Middle Ages). Based on this grammar, ANTLR then automatically generates a tailor-made software tool that can be used to analyse any text source of the same type.
However, developing this grammar is a laborious process: in addition to linguistic and historical expertise, it also requires extensive knowledge of computer science. To simplify this process, the MEPHisto team, which also includes the two doctoral students Clemens Beck and Johannes Mitschunas, is working on a grammar development environment called »Paredros.«
Following the example of its namesake—in Greek mythology, a paredros is the helper of a god—this development environment will support researchers developing grammars for structuring their data. For example, Paredros uses source texts to automatically suggest standard building blocks for the hierarchical composition of these grammars. It also automatically identifies names and places that are thematized in the source texts.
With the help of the triad of ANTLR, Paredros, and a grammar of the Vatican's stenography for the Repertorium Germanicum (developed with the help of Paredros), the researchers can now automatically generate a complex data structure for any event in the Middle Ages that is described in the Vatican's vast collection of regesta. This data structure depicts the syntactical structure of the respective regest and includes all the content-related and domain-specific facts about which this regest speaks.
Consequently, centuries after these documents were written and over 130 years after their processing began, researchers in Jena are laying the foundations for transferring the historical records in the Repertorium Germanicum project into a structured database of learned clergy members of the late Middle Ages, which will then be available for a wide range of historical research.
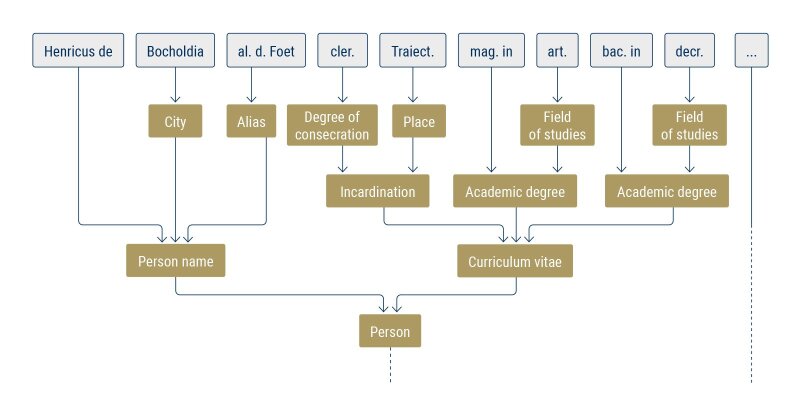
A syntax tree (parse tree) of the head of the regest entry »RG III 00057« (http://rgonline. dhi-roma.it/RG/3/57) from the »Repertorium Germanicum« generated with ANTLR. It contains information on Heinrich Foet von Bochold, a cleric (clericus) from the diocese of Utrecht (Traiectum). Foet held the academic degrees of magister in artibus and baccalarius in decretis (i.e. in canon law). In the further text of the regest it is documented that in 1410 the Pope assigned him a parish church in what is now the Netherlands.
Picture: AG MEPHisto