Big Data des Spätmittelalters
Die fakultätsübergreifende Arbeitsgruppe MEPHisto untersucht und entwickelt digitale Arbeitstechniken und Tools zur Unterstützung historischer Forschung.

Text: Ute Schönfelder
Die fakultätsübergreifende Arbeitsgruppe MEPHisto (»Modelle, Erklärungen und Prozesse in den historischen Wissenschaften«), der Forschende der Professur für Praktische Informatik II (Künstliche Intelligenz) und der Professur für Mittelalterliche Geschichte angehören, untersucht und entwickelt digitale Arbeitstechniken und Tools zur Unterstützung historischer Forschung. Das Team um Prof. Dr. Clemens Beckstein und apl. Prof. Dr. Robert Gramsch-Stehfest widmet sich in einem aktuellen Projekt der digitalen Erschließung von sogenannten Regesten. Das sind semi-strukturierte kurze Texte, die stichpunktartig die Inhalte von historischen Quellen in komprimierter Form zusammenfassen.
Konkret geht es dabei um Quellen aus dem Vatikanischen Archiv: »Die römische Kurie hatte schon im Hochmittelalter begonnen, das eigene Verwaltungsschriftgut umfassend zu dokumentieren und zu archivieren und hat so eine Unmenge an Überlieferung erzeugt, wie sie für das Mittelalter nirgendwo sonst auf der Welt zu finden ist«, sagt Robert Gramsch-Stehfest. Allerdings sind die Tausenden Handschriftenbände im Vatikan einer systematischen Erforschung nahezu unzugänglich.
Das haben Forschende bereits vor mehr als 130 Jahren erkannt und begonnen, die umfangreichen Akten in eine semi-strukturierte Form zu überführen. Das seit 1892 laufende Projekt »Repertorium Germanicum« (RG) fasst Quellenbelege aus den Vatikanischen Beständen mit Bezug zu Deutschland in einem Kurzschriftsystem zusammen, »einer Art lateinischer Stenografie«, veranschaulicht Clemens Beckstein. Die bisher erschienenen 10 Bände des RG listen zehntausende Geistliche und Gelehrte der Zeit zwischen 1378 und 1484 auf und berichten über Ereignisse, an denen diese Personen beteiligt waren. Doch auch diese Zusammenfassungen, sind für eine umfassende rechnergestützte Erforschung noch immer nicht geeignet.
Das MEPHisto-Team versucht daher mit Methoden der KI, die in den Regesten des RG enthaltenen Sachinformationen automatisch herauszufiltern und in strukturierte Daten zu überführen, die für weitergehende Analyseprozesse in einer klassischen Datenbank gespeichert und für verschiedenste wissenschaftliche Fragestellungen nutzbar sind. Dafür setzen die Forschenden ANTLR ein (ANother Tool for Language Recognition), ein Werkzeug zur automatischen Generierung von Textanalyse-Tools.

Ein mit dem KI-Programm Midjourney erstelltes Bild eines fiktiven Syntaxbaums. Das text-to-image- Tool erhielt die Anweisung (Prompt), einen »parse tree im Stil Fra Angelicos« zu erstellen. Es löste die Aufgabe durch Rückgriff auf eine im Spätmittelalter und Frühneuzeit sehr beliebte Form von Baumdarstellungen, den genealogischen Stammbaum. Offenbar ist die KI mit entsprechendem Bildmaterial trainiert worden. Fra Angelico, ein toskanischer Künstler des frühen 15. Jahrhunderts, hat selbst in Rom gewirkt. Seine Werke – überwiegend Altartafeln – zeichnen sich durch eine strenge, einfache Bildsprache aus, die Midjourney gut erfasst.
Illustration: MidjourneyUm die Regesten entsprechend einer bestimmten Fragestellung algorithmisch auswerten zu können, müssen die Forschenden zunächst eine formale Grammatik entwickeln, die die syntaktische Struktur der Regesten passend zu den Begrifflichkeiten beschreibt, über die die Regesten reden (hier also die kirchenrechtliche Begriffe des Hochmittelalters). Mithilfe dieser Grammatik erzeugt ANTLR dann vollautomatisch ein maßgeschneidertes Software-Werkzeug, das beliebige Textquellen desselben Typs analysieren kann.
Allerdings ist die Erarbeitung einer solchen Grammatik ein aufwendiger Prozess, der neben sprach- und geschichtswissenschaftlicher Expertise sehr viel Informatik-Know-how erfordert. Um diesen Prozess künftig zu erleichtern, entwickelt das MEPHisto-Team, dem auch die beiden Doktoranden Clemens Beck und Johannes Mitschunas angehören, die Grammatik-Entwicklungsumgebung »Paredros«.
Nach dem Vorbild ihres Namensgebers – in der griechischen Mythologie ist ein Paredros der Helfer eines Gottes – soll diese Entwicklungsumgebung Forschende bei der Erarbeitung von Grammatiken zur Strukturierung ihrer Daten unterstützen: etwa dadurch, dass »Paredros« anhand der Quelltexte automatisch Standardbausteine für die hierarchische Komposition dieser Grammatiken vorschlägt oder dadurch, dass es Namen und Orte, die in den Quelltexten thematisiert werden, automatisch identifiziert.
Mit Hilfe des Dreiklangs aus ANTLR, Paredros und einer – unterstützt von Paredros – passend zum Repertorium Germanicum entwickelten Grammatik der Regestenstenografie lässt sich so für beliebige mittelalterliche Ereignisse, die in dieser riesigen Sammlung von Regesten des Vatikans beschrieben sind, automatisch eine komplexe (Daten-)Struktur generieren, die neben dem syntaktischen Aufbau des Regests auch all die inhaltlichen und domänenspezifischen Sachverhalte darstellt, über die dieser Regest redet.
Damit legen die Jenaer Forschenden die Grundlage dafür, dass das überlieferte historische Material des Repertorium Germanicum Jahrhunderte nach seiner Entstehung und mehr als 130 Jahre nach Beginn seiner Aufarbeitung in eine strukturierte Datenbank der gelehrten Kleriker des Spätmittelalters fließen kann, die dann für vielfältige historische Forschungen zur Verfügung steht.
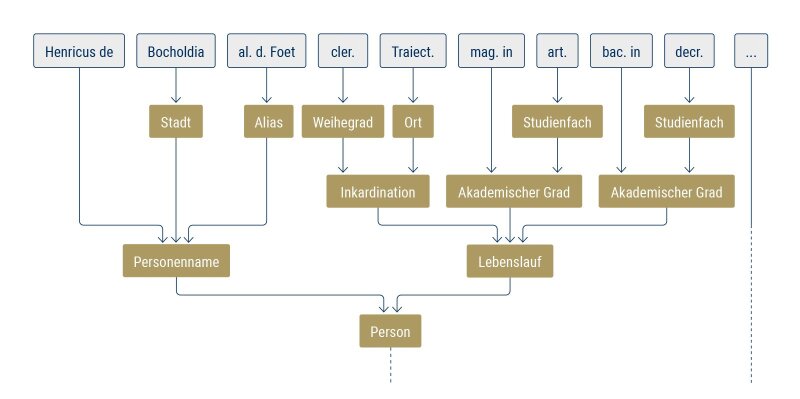
Ein mit ANTLR generierter Syntaxbaum (parse tree) des Kopfs des Regesteneintrags »RG III 00057« aus dem »Repertorium Germanicum«. Er enthält Informationen zu Heinrich Foet von Bochold, eines Geistlichen (clericus) aus dem Bistum Utrecht (Traiectum). Foet trug die akademischen Grade eines magister in artibus und baccalarius in decretis (d. h. im Kirchenrecht). Im weiteren Regestentext wird dokumentiert, dass ihm im Jahr 1410 durch den Papst eine Pfarrkirche in den heutigen Niederlanden zugewiesen wurde.
Abbildung: AG MEPHisto